Unit 6: Natural Language Processing
Question 1: What is NLP? Explain with an example.
Answer: Natural Language Processing, or NLP, is a sub-field of AI that is focused on enabling computers to understand and process human languages. The most important objective of Natural Language Processing is to read, understand, and make sense of the human language in a useful way.
Question 2: Explain applications of Natural Language Processing with respect to Automatic Summarization, Sentiment Analysis, Text classification and Virtual Assistants.
Answer: Applications of Natural Language Processing:
• Automatic Summarization: This application of NLP is relevant not only for summarizing the meaning of documents and information, but also to understand the emotional meanings within the information, such as in collecting data from social media. Automatic summarization is especially relevant when we need an overview of a news item or blog post, while avoiding redundancy from multiple sources and maximizing the diversity of content obtained.
• Sentiment Analysis: The objective of sentiment analysis is to identify sentiment among numerous posts or even in the same post where emotion is not always explicitly expressed. Sentiment analysis is used by companies to identify opinions and sentiment online to help them understand what customers think about their products and services and overall indicators of their reputation. Beyond determining simple polarity, sentiment analysis understands sentiment in context to help better understand what's behind an expressed opinion, which can be extremely relevant in understanding and driving purchasing decisions. For example, sentiment analysis helps the company what the user thinks about their product in his/her comment "I love the new iPhone" and, a few lines later "But sometimes it doesn't work well".
• Text classification: Text classification enables us to assign predefined categories to a document and organize it to help find the information you need or simplify some activities. For example, an application of text categorization is spam filtering in email.
• Virtual Assistants: Nowadays virtual assistants like Google Assistant, Cortana, Siri, Alexa, etc. have become an integral part of our lives. We can use them as text-only interface or as spoken dialog system. They not only can communicate with us but they also have the ability to make our lives easier. By accessing our data, they can help us in making calls for us, send messages and a lot more.
Question 3: What is CBT? Write about the goal of the project.
Answer: CBT stands for Cognitive Behavioural Therapy. CBT is a technique used by most therapists to cure patients out of stress and depression. It is considered to be one of the best methods to address stress as it is easy to implement on depressed people and also gives good results. This therapy includes understanding the behaviour and mindset of a person in their normal life. With the help of CBT, therapists help people overcome their stress and live a happy life. The goal of the project is:
"To create a chatbot which can interact with people, help them to vent out their feelings and take them through primitive CBT."
Question 4: Explain about the CBT project cycle.
Answer: The CBT Project Cycle include:
→ Problem Scoping
CBT is a technique which is used by most therapists to cure patients out of stress and depression. But it has been observed that people don’t wish to seek the help of a psychiatrist willingly. As a result they try to avoid such interactions as much as possible. Thus, there is a need to bridge the gap between a person who needs help and the psychiatrist. Let us now look at various factors around this problem through the 4Ws problem canvas.
• Who canvas - Who has the problem?
|
Who are the stakeholders? |
People who suffer from stress and are on the onset of depression |
|
What do we know about them? |
People who are going through stress are reluctant to consult a psychiatrist. |
• What canvas - What is the nature of problem?
|
What is the problem? |
People who need help are reluctant to consult a psychiatrist and hence live miserably. |
|
How do you know that it is a problem? |
Studies around mental stress and depression are available on various authentic sources. |
• Where canvas - Where does the problem arise?
|
What is the context/situation in which the stakeholders experience this problem? |
• When they are going through a stressful period of time |
• Why canvas - Why do you think it is a problem worth solving?
|
What would be of key value to the stakeholders? |
• People get a platform where they can talk and vent out their feeling
anonymously |
|
How would it improve their situation? |
• People would be able to vent out their stress |
Now that we have gone through all the factors around the problem, the problem statement templates go as follows:
|
Our |
People undergoing stress |
Who? |
|
Have a problem of |
Not being able to share their feelings |
What? |
|
While |
They need help in venting out their emotions |
Where? |
|
An ideal solution would |
Provide them a platform to share their thoughts anonymously and suggest help whenever required |
Why? |
This leads us to the goal of the project:
"To create a chatbot which can interact with people, help them to vent out their feelings and take them through primitive CBT."
→ Data acquisition
To understand the sentiments of people, we need to collect their conversational data so the machine can interpret the words that they use and understand their meaning. Such data can be collected from various means like surveys, observing the therapist’s sessions, databases available on internet, interviews etc.
→ Data exploration
Once the textual data has been collected, it needs to be processed and cleaned so that an easier version can be sent to the machine. Thus, the text is normalised through various steps and is lowered to minimum vocabulary since the machine does not require grammatically correct statements but the essence of it.
→ Modelling
Once the text has been normalised, it is then fed to an NLP based AI model. Depending upon the type of chatbot we try to make, there are a lot of AI models available which help us build the foundation of our project.
→ Evaluation
The model trained is then evaluated and the accuracy for the same is generated on the basis of the relevance of the answers which the machine gives to the user’s responses. To understand the efficiency of the model, the suggested answers by the chatbot are compared to the actual answers.
Question 5: Explain 4Ws of problem scoping.
Answer: The 4Ws of problem scoping stand for Who, What, Where and Why.
• Who canvas: The "Who" block helps in analysing the people getting affected directly or indirectly due to it. Under this, we find out who the "Stakeholders" to this problem are and what we know about them. Here is the Who Canvas:
Who is having the problem?
1. Who are the stakeholders?
_______________________________
_______________________________
2. What do you know about them?
_______________________________
_______________________________
• What canvas: Under the "What" block, you need to determine the nature of the problem (i.e. What is the problem and how do you know that it is a problem?). Under this block, you also gather evidence to prove that the problem you have selected actually exists.
What is the nature of the problem?
1. What is the problem?
_______________________________
_______________________________
2. How do you know it is a problem?
_______________________________
_______________________________
• Where canvas: This block will help you look into the situation in which the problem arises, the context of it, and the locations where it is prominent.
Where does the problem arise?
1. What is the context/situation in which the stakeholders experience the problem?
_______________________________
_______________________________
• Why canvas: Since all the major elements that affect the problem directly are listed down, now it is convenient to understand who the people that would be benefitted by the solution are; what is to be solved; and where will the solution be deployed. These three canvases now become the base of why you want to solve this problem. Thus, in the “Why” canvas, we think about the benefits which the stakeholders would get from the solution and how it will benefit them as well as the society.
Why do you believe it is a problem worth solving?
1. What would be of key value to the stakeholders?
_______________________________
_______________________________
2. How would it improve their situation?
_______________________________
_______________________________
Question 6: How are overfit, underfit and perfect fit related to Evaluation?
Answer: To understand the efficiency of the model, the suggested answers by the model are compared to the actual answers. There are 3 cases related to evaluation:
• Underfitting: In the first case, the model’s output does not match the true function at all. Hence the model is said to be underfitting and its accuracy is lower.
• Perfect fit: In the second case, the model’s performance matches well with the true function which states that the model has optimum accuracy and the model is called a perfect fit.
• Overfitting: In the third case, model performance is trying to cover all the data samples even if they are out of alignment to the true function. This model is said to be overfitting and this too has a lower accuracy.
Question 7: What is chat-bot? State the concept used in its implementation.
• Which chatbot did you try? Name it.
• What is the purpose of this chatbot?
• How was the interaction with the chatbot?
• Did the chat feel like talking to a human or a robot? Why do you think so?
• Do you feel that the chatbot has a certain personality?
Answer:
A chatbot is an artificially intelligent machine that can converse with humans. This conservation can be text-based or spoken. Chatbots are fundamentally used for the acquisition of information. Chatbots are powerful representation of the scope of AI. The concept used in chatbots is NLP or Natural Language Processing.
• I tried a chatbot named Jabberwacky developed by Rollo Carpenter.
• The aim for its creation is to stimulate natural human conversations through involvement of humorous elements to keep chats interesting, captivating and life-like.
• The interaction with Jabberwacky was interesting, and even humorous. It has a good selection of words.
• Chatting with this chatbot felt as if talking to a human. This was because it is artificial chatbot programmed to chat on its own without anyone’s support.
• Yes I feel that this chatbot has a certain personality.
Question 8: Write about 2 types of chatbots around us.
Answer: There are 2 types of chatbots around us:
• Script bot: Script bots are those chatbots that work around with a script which is programmed in them. These chatbots are easy to make. They have no or little processing skills and have limited funtionality. These chatbots are mostly free and are easy to integrate to a messaging platform.
• Smart bot: Smart bots are those chatbots that are flexible and powerful. These chatbots have a wide functionality. Also these chatbots work on bigger databases and other resources. They learn with more data. Smart bots learn with more data. To make a smart bot, coding is required.
Question 9: Differentiate between Script-bot and Smart-bot.
Answer:
|
Script-bot |
Smart-bot |
|
Script bots are easy to make |
Smart-bots are flexible and powerful |
|
Script bots work around a script which is programmed in them |
Smart bots work on bigger databases and other resources directly |
|
Mostly they are free and are easy to integrate to a messaging platform |
Smart bots learn with more data |
|
No or little language processing skills |
Coding is required to take this up on board |
|
Limited functionality |
Wide functionality |
Question 10: Explain the concept of following with respect to Computer Language processing:
a. How are Human Language and Computer Language processed?
b. Analogy with programming language.
c. “Multiple Meanings of a word in NLP” Justify.
d. Perfect Syntax, no Meaning.
Answer:
a) Humans communicate through language which we process all the time. Our brain keeps on processing the sounds that it hears around itself and tries to make sense out of them all the time. The sound reaches the brain through a long channel. As a person speaks, the sound travels from his mouth and goes to the listener’s eardrum. The sound striking the eardrum is converted into neuron impulse, gets transported to the brain and then gets processed. After processing the signal, the brain gains understanding around the meaning of it. If it is clear, the signal gets stored. Otherwise, the listener asks for clarity to the speaker. This is how human languages are processed by humans. On the other hand, the computer understands the language of numbers. Everything that is sent to the machine has to be converted to numbers. While typing, if a single mistake is made, the computer throws an error and does not process that part. The communications made by the machines are very basic and simple.
b)
• Different syntax, same semantics:
For example, 2 + 3 = 3 + 2
Here, the way these statements are written is different, but their meanings are the same that is 5.
• Different semantics, same syntax:
For example, 2/3 (Python 2.7) ≠ 2/3 (Python 3)
Here the statements written have the same syntax but their meanings are different. In Python 2.7, this statement would result in 1 while in Python 3, it would give an output of 1.5.
c) To explain this concept let us take the following example:
He parked his car to let his children go in the park.
In the above sentence the word ‘park’ means 2 things. In the first context, the word park means the act of positioning the car to stop it and in the second context the word park refers to a garden.
d) Sometimes, a statement can have a perfectly correct syntax but it does not mean anything. For example:
Cars paint cautiously while the doctors turn west.
This statement is correct grammatically but it doesn’t make any sense. In human language, a perfect balance of syntax and semantics is important for better understanding.
Question 11: Is Text Normalization part of Data Processing? Explain.
Answer: Since the language of computers is numerical, therefore the very first step is to convert our language to numbers. This conversion takes a few steps to happen. The first step to it is Text Normalisation. Since human languages are complex, we need to first of all simplify them in order to make sure that the understanding becomes possible. Text Normalisation helps in cleaning up the textual data in such a way that it comes down to a level where its complexity is lower than the actual data. In Text Normalisation, several steps are undertaken to normalise the text to a lower level.
Question 12: What is corpus? Is it important? Justify.
Answer: The term used for the whole textual data from all the documents altogether is known as corpus. Corpus is necessary as in text normalisation we’ll working on a collection of written text.
Question 13: Explain Text normalization from documents to bag of words.
Answer: In Text Normalisation, we undergo several steps to normalise the text to a lower level. We will be working on text from multiple documents. Let us take a look at the steps:
• Sentence Segmentation: Under sentence segmentation, the whole corpus is divided into sentences. Each sentence is taken as a different data so now the whole corpus gets reduced to sentences.
• Tokenisation: After segmenting the sentences, each sentence is then further divided into tokens. Under tokenisation, every word, number and special character is considered separately and each of them is now a separate token.
• Removing Stopwords, Special Characters and Numbers: In this step, the tokens which are not necessary are removed from the token list. Stopwords are the words which occur very frequently in the corpus but do not add any value to it. Humans use grammar to make their sentences meaningful for the other person to understand. But grammatical words do not add any essence to the information which is to be transmitted through the statement hence they come under stopwords. Some examples of stopwords are 'a', 'an', 'and', 'are', 'as' etc. These words occur the most in any given corpus but talk very little or nothing about the context or the meaning of it. Hence, to make it easier for the computer to focus on meaningful terms, these words are removed.
Along with these words, our corpus might have special characters and/or numbers. Now it depends on the type of corpus that we are working on whether we should keep them in it or not. For example, if you are working on a document containing email IDs, then you might not want to remove the special characters and numbers whereas in some other textual data if these characters do not make sense, then you can remove them along with the stopwords.
• Converting text to a common case: After the stopwords removal, we convert the whole text into a similar case, preferably lower case. This ensures that the case-sensitivity of the machine does not consider same words as different just because of different cases.
• Stemming: In this step, the remaining words are reduced to their root words. In other words, stemming is the process in which the affixes of words are removed and the words are converted to their base form. Note that in stemming, the stemmed words (words which are we get after removing the affixes) might not be meaningful. For example,
|
Word |
Affixes |
Word after stemming |
Successful or not |
|
healed |
-ed |
heal |
Successful |
|
studies |
-ies |
stud |
Unsuccessful |
|
studying |
-ing |
study |
Successful |
|
troubling |
-ing |
troubl |
Unsuccessful |
In the above example you can see healed and studying were reduced to a meaningful word whereas studies and troubling were reduced to a meaningless word. Stemming does not take into account if the stemmed word is meaningful or not. It just removes the affixes hence it is faster.
• Lemmatization: Stemming and lemmatization have same role - removal of affixes. But the difference between both of them is that in lemmatization, the word we get after affix removal (also known as lemma) is a meaningful one. Lemmatization makes sure that lemma is a word with meaning and hence it takes a longer time to execute than stemming. For example,
|
Word |
Affixes |
Word after stemming |
Successful or not |
|
healed |
-ed |
heal |
Successful |
|
studies |
-ies |
study |
Successful |
|
studying |
-ing |
study |
Successful |
|
troubling |
-ing |
trouble |
Successful |
As you can see in the above example, the output for healed, studies, studying, and troubling after affix removal has become a meaningful word instead of a meaningless one. With this we have normalised our text to tokens which are the simplest form of words present in the corpus. Now it is time to convert the tokens into numbers. For this, we would use the Bag of Words algorithm.
• Bag of Words: Bag of Words is a NLP model which helps in extracting features out of the text which can be helpful in machine learning algorithms. In bag of words, we get the occurrences of each word and construct the vocabulary for the corpus. Here calling this algorithm "bag" of words symbolises that the sequence of sentences or tokens does not matter in this case as all we need are the unique words and their frequency in it.
Question 14: What are stop words? Give 4 examples.
Answer: Stop words are those words which occur the most in almost all the documents. But these words do not talk about the corpus at all. Though they are important for humans as they make the statements understandable to us, for the machine they are a complete waste as they do not provide us with any information regarding the corpus. Hence, these are termed as stopwords and are mostly removed at the pre-processing stage only. Example, and, into, there, on etc.
Question 15: "Lemmatization is difficult process compared to Stemming". Explain with example.
Answer: Lemmatization is a difficult process compared to Stemming. This is because lemmatization performs its task using vocabulary and morphological analysis of words. It removes inflectional endings only and obtains the base or dictionary form of the word, known as lemma. Since lemmatization makes sure that lemma is a word with meaning therefore it takes a longer time to execute than stemming.
Question 16: Differentiate between Lemmatization and Stemming.
Answer:
|
Stemming |
Lemmatization |
|
In stemming, the words are reduced to their root words. |
In lemmatization, the words are reduced to their dictionary form. |
|
Stemming is an easy process. |
Lemmatization is a difficult process when compared to stemming. |
|
It doesn’t take into account if the word is meaningful or not. |
It takes into account if the word is meaningful or not. |
Question 17: "The bag of words gives us two things". What are they?
Answer: In bag of words, we get the occurrences of each word and construct the vocabulary for the corpus.
Question 18: Explain the step-by-step approach to implement bag of words algorithm.
Answer: Following is the step-by-step approach to implement bag of words algorithm:
Step 1: Text Normalisation
Collect data and pre-process it
Step 2: Create Dictionary
Make a list of all the unique words occurring in the corpus. (Vocabulary)
Step 3: Create document vectors
For each document in the corpus, find out how many times the word from the unique list of words has occurred.
Step 4: Create document vectors for all the documents.
Question 19: Build the document vector table for corpus of your choice.
Answer:
Step 1: Collecting data and pre-processing it.
• Document 1: Ramu and Mofta are stressed.
• Document 2: Ramu went to a therapist.
• Document 3: Mofta went to download a meditation chatbot.
After text normalisation, the text becomes:
• Document 1: [ramu, and, mofta, are, stressed, .]
• Document 2: [ramu, went, to, a, therapist, .]
• Document 3: [mofta, went, to, download, a, meditation, chatbot, .]
Note that no tokens have been removed in the stopwords removal step. It is because the frequency of all the words is almost the same, therefore, no word can be said to have lesser value than the other.
Step 2: Create Dictionary
Go through all the steps and create a dictionary i.e., list down all the words which occur in all three documents:
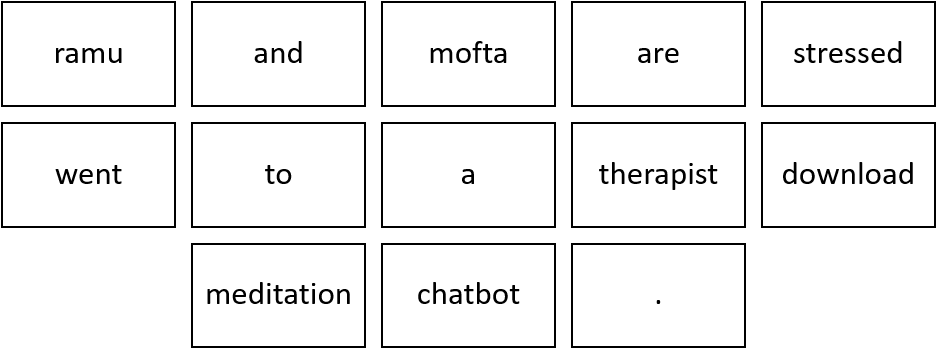
Note that even though some words are repeated in different documents, they are all written just once as while creating the dictionary, we create the list of unique words.
Step 3: Create document vector
In this step, the vocabulary is written in the top row. Now, for each word in the document, if it matches with the vocabulary, put a 1 under it. If the same word appears again, increment the previous value by 1. And if the word does not occur in that document, put a 0 under it.
|
ramu |
and |
mofta |
are |
stressed |
went |
to |
a |
therapist |
download |
meditation |
chatbot |
. |
|
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
Since the first document have words (ramu, and, mofta, are, stressed, .) so, all these words get a value of 1 and rest of the words get a 0 value.
Step 4: Repeat for all documents
Same exercise has to be done for all the documents. Hence, the table becomes:
|
ramu |
and |
mofta |
are |
stressed |
went |
to |
a |
therapist |
download |
meditation |
chatbot |
. |
|
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
|
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
|
0 |
0 |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
In this table, the header row contains the vocabulary of the corpus and three rows correspond to three different documents. Finally, this gives us the document vector table for our corpus.
Question 20: What is token?
Answer: Tokens is a term used for any word or number or special character occurring in a sentence.
Questio 21: What is document vector table?
Answer: The table in which the header row contains the vocabulary of the corpus and below rows correspond to the different documents is called document vector table. Document Vector Table is used while implementing Bag of Words algorithm. If the document contains a particular word it is represented by 1 and absence of word is represented by 0 value.
Question 22: How is NLP related to AI? Write its importance.
Answer: Natural Language Processing, or NLP, is the sub-field of AI that is focused on enabling computers to understand and process human languages. AI is a subfield of Linguistics, Computer Science, Information Engineering, and Artificial Intelligence is concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyse large amounts of natural language data. Since Artificial Intelligence nowadays is becoming an integral part of our lives, its applications are very commonly used by the majority of people in their daily lives. Some of the applications of NLP which are used in the real-life scenario include Automatic summarisation, sentiment analysis, virtual assistants etc.
No comments:
Post a Comment